Dashboard: Cluster Ops
RapidFire AI is designed to work with any type of cloud backend. On-Demand instances are common for DL workloads on public clouds. Leaving such clusters running when they are not being actively used (say, overnight or when you are away for a few hours) is a costly waste of resources.
Cluster ops are a convenient mechanism to stop and restart your RapidFire AI cluster. All cluster ops can be seen on the app under the “Clusters” tab in the “Actions” column.
As of this writing, we offer 2 cluster ops in the self-service Free Trial Tier: Stop and Resume. In the self-service paid Pro Tier, we offer 2 additional cluster ops: Create and Delete.
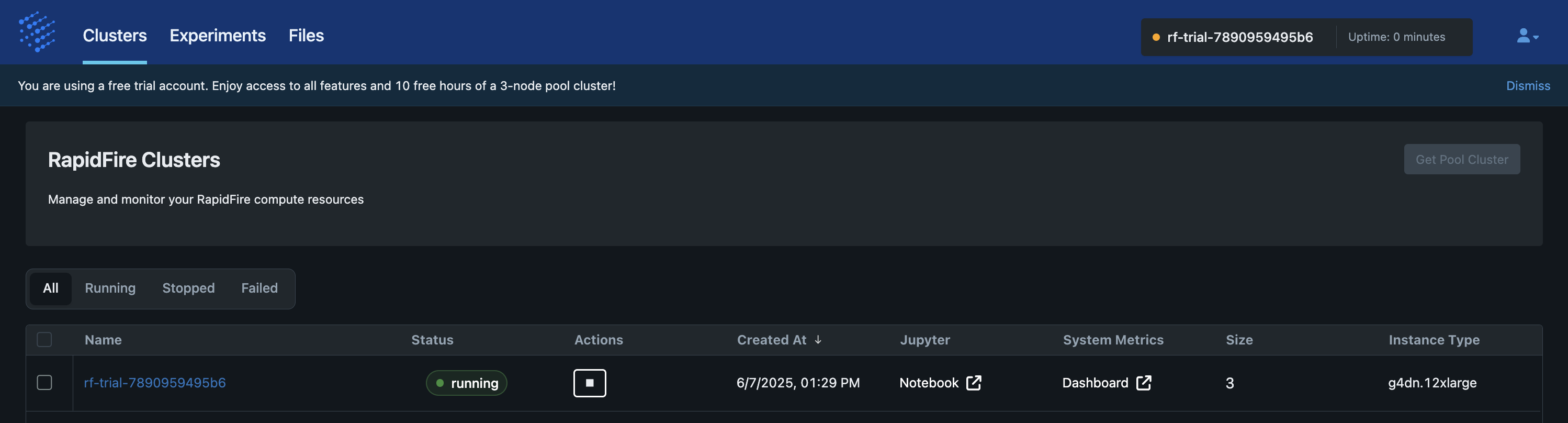
Stop Cluster
This op stops a “Running” cluster and moves it to “Stopped” status. It simply terminates all EC2 instances of the cluster, both the controller and workers. Note that the filesystem is still kept alive (more note below). While the infrastructure is being torn down, the cluster status is shown as “Stopping” on the app. Stop typically takes about 5-10min to finish.

Restart Cluster
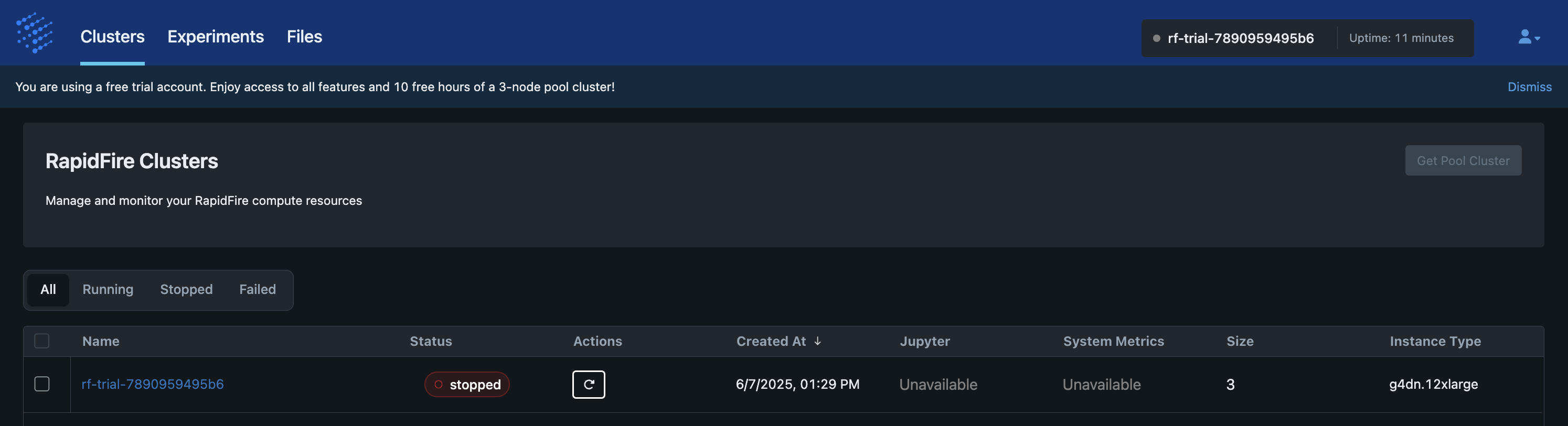
This op restarts a “Stopped” cluster and moves it back to “Running” status. It launches new On-Demand EC2 instances for the cluster, reinstalls required dependencies and packages, and starts all RapidFire AI processes again. While the infrastructure is being set up, the cluster status is shown as “Restarting” on the app. Restart typically takes about 5-10min to finish.

Notes:
The cluster’s filesystem is kept alive across Stop-Restart of a cluster.
This provides you with a very useful illusion as if the cluster was never stopped!
You can also stop and restart the cluster in the midst of an experiment, say, between two
different run_fit() ops.
All of your local files on the Jupyter server, including (saved) code notebooks and auxiliary files you uploaded, all MLflow metrics logs of past experiments, and model checkpoints of a currently alive experiment (if any) will be available to use after Restart.
Important:
Please do NOT Stop the cluster when any op is actively running.
First click “stop” on that running op’s cell on Jupyter and then invoke an explicit
cancel_current() op in a new cell.
Otherwise, the system might end up in an inconsistent state after Restart, and you might
not be able to access that experiment’s artifacts or run new experiment ops.
Create Cluster
This op makes it simple to obtain new ephemeral or persistent clusters with your desired configuration of number of workers, worker instance type, and AWS region. So, you can freely create separate clusters for separate workloads, e.g., a 3-worker cluster with expensive L40S GPUs for an NLP use case with a large Transformer but small data or a 20-worker cluster with cheap T40 GPUs for a CV use case with a small CNN but large data.
This op automates all of the following actions for your benefit: acquire EC2 instances, configure the network and filesystem, and install all dependencies and RapidFire AI. During cluster creation, the status is shown as “Creating” on the app.
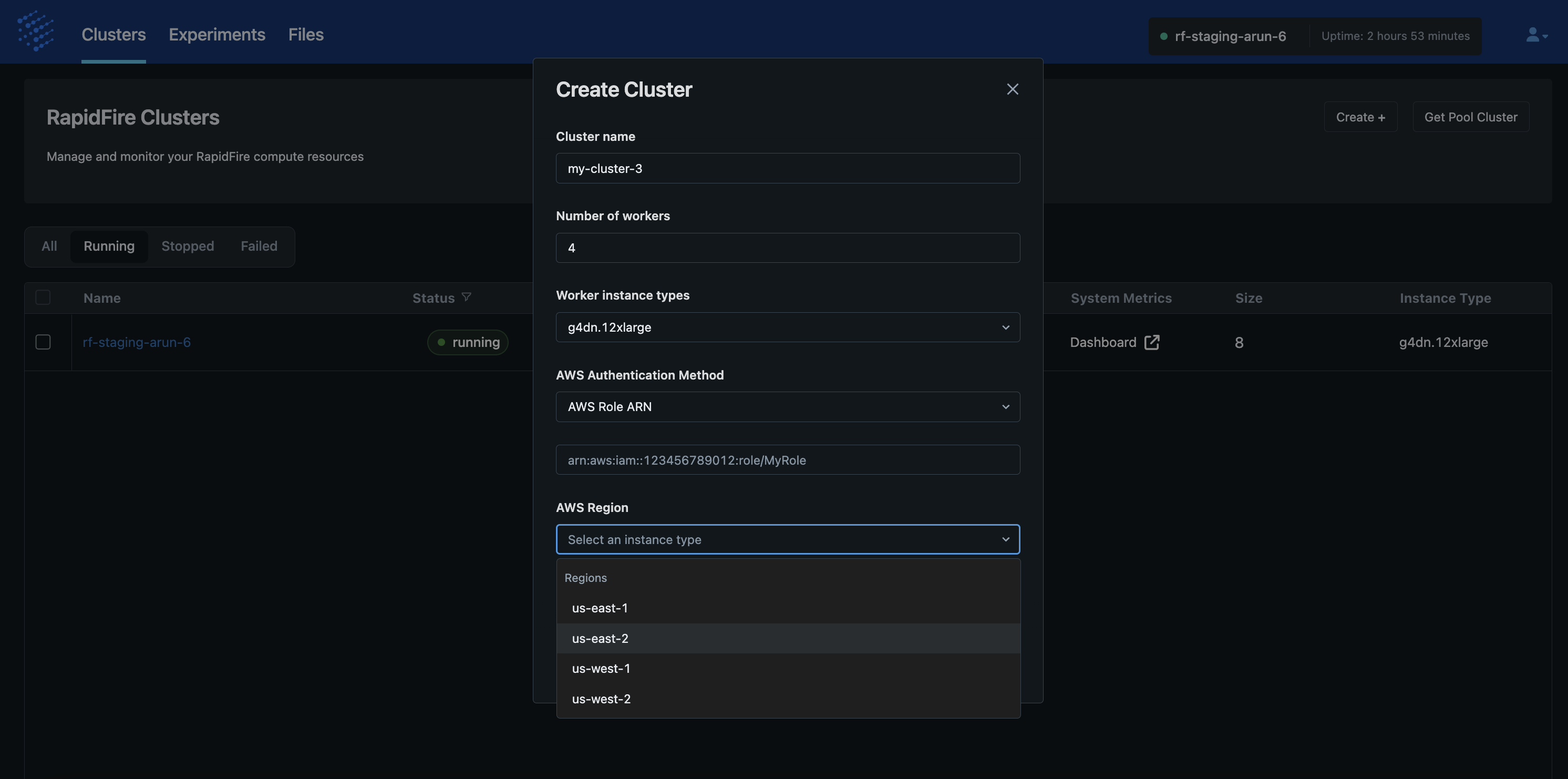
Create typically takes about 50-55min to finish depending on current AWS availability. If not enough instances are available in that region at that point in time, Create will report a failure; if that happens, we suggest altering your desired cluster configuration if possible (region, instance type, and/or worker count) or just retrying later.
Note that only AWS On-Demand instances are supported for now; we plan to add support for Spot and Serverless instances, as well as other clouds in the future based on feedback and demand.
Delete Cluster
This op deletes a cluster altogether and returns all used resources to AWS. It terminates all EC2 instances, filesystems, network, and other resources. While the resources are being deleted, the cluster status is shown as “Deleting” on the app. Delete typically takes about 5-10min to finish.
Note that this op will delete any files on your Jupyter server as well.
So, we suggest downloading a copy of those files if needed before invoking Delete.
However, all experiment artifacts persisted to S3 via end() will remain available on S3.
Cluster Logs
A log of all cluster operations is available for your to view on the RapidFire AI app. On the “Clusters” tabs click on the cluster name to see its log.
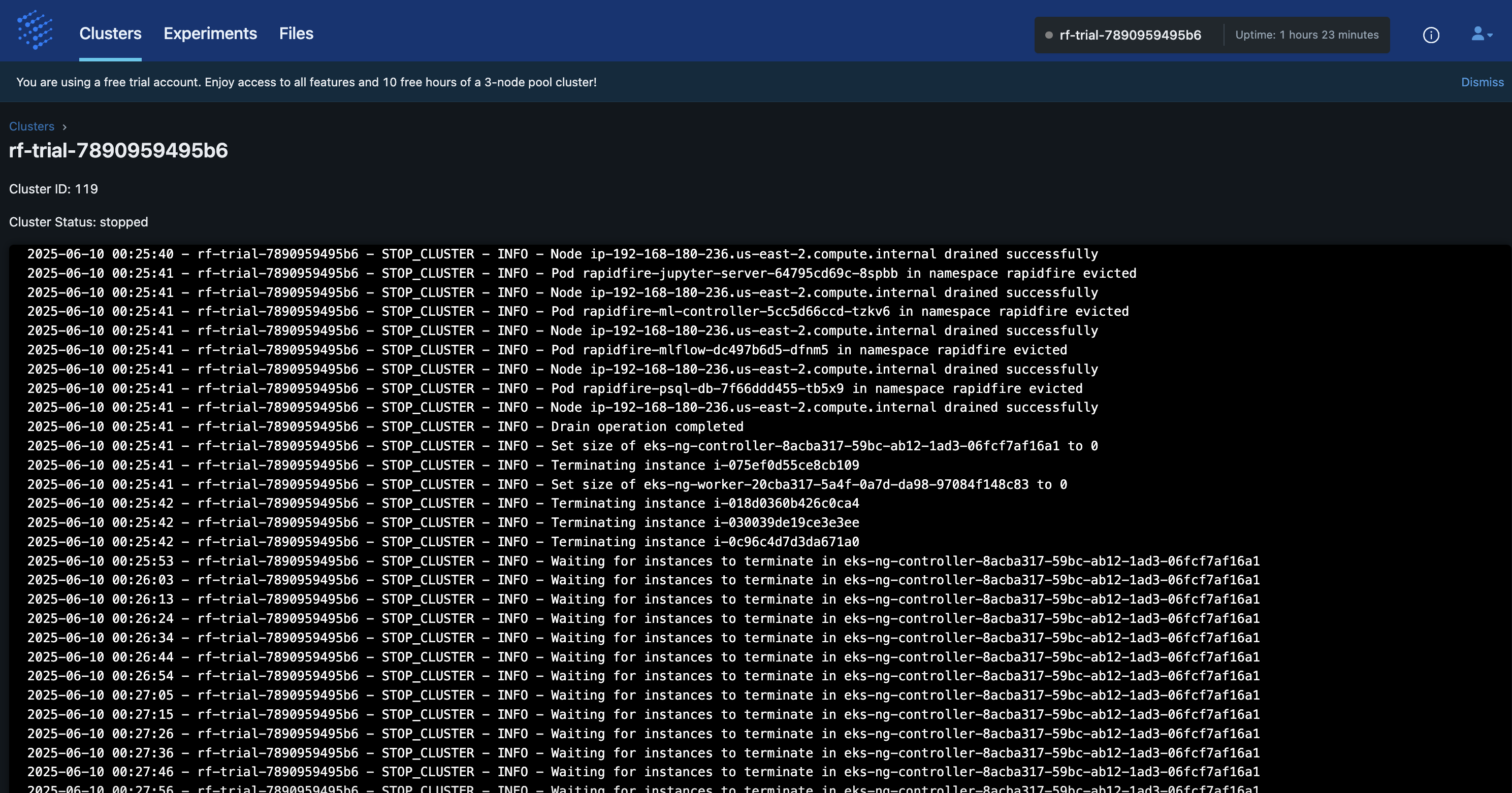
The entries show a record of everything from when the cluster was created to all your cluster ops.
Degraded Clusters
We run a continual health check on all clusters to make sure there is no degradation of the running services. If you see a cluster move to the “degraded” state, that means some services will be unavailable, including features like file upload, until the cluster recovers.
It will automatically moved to the “failed” state if it fails too many health checks. Please contact support team if you see any unexpected behavior, or if a cluster is stuck in the wrong state for too long.
Failed Clusters
In rare cases, when deleting, restarting, or stopping a cluster it is possible that it could move to a “failed” state due to some unexpected AWS-related issues. There is a recovery mechanism for clusters to self-correct.
If your cluster stays in the “failed” state without self-correcting, please contact our support team for further assistance.
Bring Your AWS Account
In the soon to be released self-service paid Pro Tier, we will offer the option of securely accepting your AWS account information to launch and manage On-Demand clusters in your VPC instead of with the RapidFire AI AWS account. So, your datasets and models will NOT leave your VPC, offering even stronger data privacy.
However, note that the RapidFire AI web app still runs on our VPC to handle control plane tasks to run computations by pairing with your cluster VPC. The billing of credits for this form factor will differ from self-service on our AWS account. Read more here: Pricing and Credits.
In the soon to be released Enterprise Tier, we will also offer the option of securely accepting not just AWS account information but also connecting with your pre-existing reserved/dedicated EKS cluster. This will enable you to maximize the return on your GPU investments with the power of rapid experimentation.
Please email us at contact@rapidfire.ai for more details on the above options, including customized pricing with applicable discounts for the Enterprise Tier.
On-Premise and Other Clouds
In the near future we also plan to offer RapidFire on premise in the Enterprise Tier. This will include installation, continual white-glove servicing/support, and priority for upgrades. All that will enable you to maximize the return on your GPU infrastructure investment by leveraging the power of rapid experimentation.
In the future, we also plan to expand the self-service tiers to other public clouds (GCP, Azure, Oracle), AI-focused hyperscalers, and hybrid cloud plus on-premise clusters.
Please email us at contact@rapidfire.ai if you are interested in any of the above options.