API: Data Ingestion
RapidFire AI is a natively multimodal AI system. Thus, our ingestion scheme is designed to be intuitive, flexible, and highly general to support AI use cases across all data modalities–image, text, time series, video, audio, tabular, and multimodal.
As of this writing, we support only S3 for persistent storage of all input/output files for ingestion/egress. We will keep expanding this API to support more storage options based on feedback.
Our ingestion mechanism has 3 key components: Example Structure File (ESF), Locators dictionary, and Data Handle class. This page dives deeper into the first two; see API: Data Handle for details on how ESF and locators get used.
Example Structure File (ESF)
This is a core concept in RapidFire AI. This file just has a table/DataFrame whose columns specify the “schema” of an example for your use case.
Each row corresponds to one example needed for gradient and/or inference computation. The columns can be of 3 types:
Identifier: A unique identifier integer per example. This must be a single column named “id” (lower case).
In-situ Column: A column for a feature or label/target whose values are present in place in the ESF itself. These could be numbers, strings, or even dictionaries–any data type serializable via CSV files.
Object Column: A column for an object file represented with a relative file path to a remote object, relative to the object directory in your locators (explained below). Object files can be of any file type: JPG, TXT, JSON, MPEG, MP4, DOC, PDF, etc. Both features and targets can be objects, e.g., for image captioning, the input image is an object column but for image generation from text, the target is an object column.
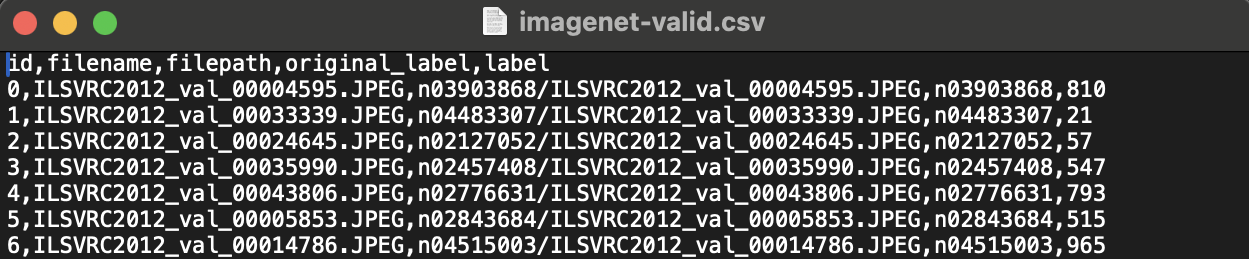
As you can see, the ESF is a highly general mechanism to ingest any multimodal dataset. Here is an example of a simple ESF from the ImageNet tutorial use case (image input; number output).
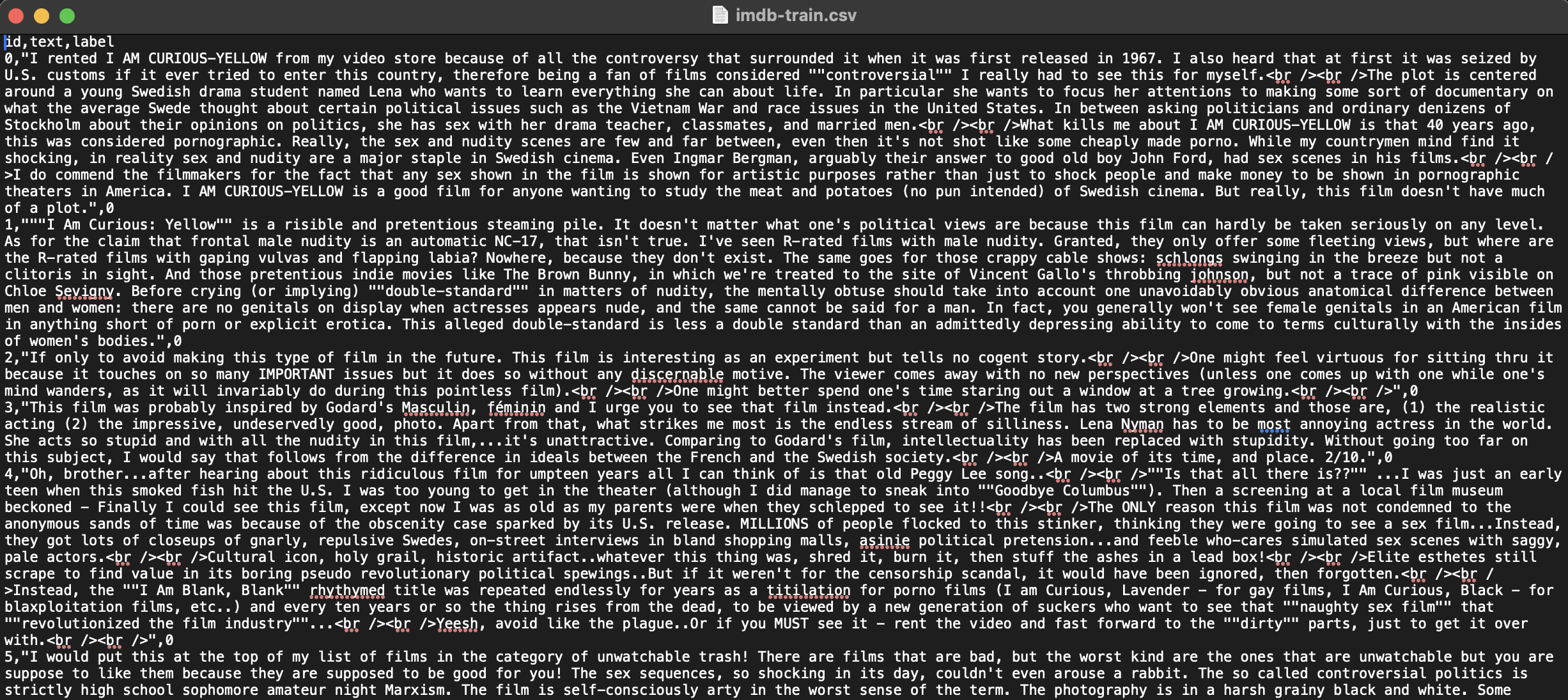
Here is another example ESF from the IMDB tutorial use case (text input; number output). This dataset is fully in-situ, i.e., there are no object columns.
It is not necessary that every example in the ESF must be have values for every column.
In this sense, the ESF behaves as a flattened table capturing any semistructured data.
You have full freedom to handle missing cells and/or other column-specific semantics in your row_prep() function.
You can indicate separate ESFs for up to 4 separate data partitions in your locators: train, validation, test, and prediction. The prediction set’s ESF need not have the target/label column(s) unlike the other three.
As of this writing, we support the ESF being only in CSV textual format. We plan to add support for more formats and ingestion mechanisms based on feedback.
Locators Dictionary and Semantics
This is another core concept in RapidFire AI. Locators tell the system where to ingest data from.
Locators are captured in a single Dict[str, Any] dictionary in which a key is a reserved
string and a value is a string representing a file/directory (for most of them).
We dive into the structure and semantics of the locators dictionary with the following example adapted from the ImageNet tutorial notebook.
Example:
ImageNetLocators = {
"train_main": "s3://rapidfire-datasets-us-west-2/imagenet/Metadata/train.csv",
"validation_main": "s3://rapidfire-datasets-us-west-2/imagenet/Metadata/valid.csv",
"test_main": "s3://rapidfire-datasets-us-west-2/imagenet/Metadata/valid.csv",
"predict_main": "s3://rapidfire-datasets-us-west-2/imagenet/Metadata/test.csv",
"train_dir": "s3://rapidfire-datasets-us-west-2/imagenet/Data/train",
"validation_dir": "s3://rapidfire-datasets-us-west-2/imagenet/Data/val",
"test_dir": "s3://rapidfire-datasets-us-west-2/imagenet/Data/val",
"predict_dir": "s3://rapidfire-datasets-us-west-2/imagenet/Data/test",
"misc": [
"s3://rapidfire-datasets-us-west-2/imagenet/Metadata/imagenet_label_mapping.json"
],
}
As illustrated above, the locators have 3 main groups of key-value pairs. Let us dive deeper into each.
ESFs
These are absolute paths to the ESFs on remote storage for the corresponding data partition. This group has 4 reserved key strings:
train_main: Used for all model training duringrun_fit()validation_main: Used for all model validation duringrun_fit()test_main: Used for allrun_test()predict_main: Used for allrun_predict()
It suffices to list only the subset of locators needed for the respective function.
For instance, for batch inference with run_predict() you can list only predict_main.
Note that it is also fine for you to reuse files across some of these locators depending on your use case. In the example above, note how the validation and test partitions reuse the same ESF.
Object Directories
These are absolute paths to the directories on remote storage with all objects files of the corresponding data partition.
This group also has 4 reserved key strings, with equivalent semantics to their corresponding ESFs listed above:
train_dir, validation_dir, test_dir, and predict_dir.
You have full freedom to organize the internal subdirectory structure of an object directory however you want. Just note that the object directory path specified in your locators forms the exact prefix for all file paths in any object column in your corresponding ESF. So, please make sure to accurately reflect your internal subdirectory structure in your ESF.
Again, it suffices to list only the subset of locators needed for the respective function. You can also reuse directories across locators as per you use case. But please make sure that for each data partition (say, test), both ESF and object directory locator are listed (unless it is an in-situ dataset, in which case ESF alone suffices).
Miscellaneous Files
This is an optional read-only locator under the reserved key string misc.
Its value must be a List type, with the list elements being absolute paths
on remote storage to any auxiliary files that you plan to read in your code.
All of these files will be downloaded and made available locally on the cluster.
In the above example, the JSON file listed has the label string-number mapping will be read in initialize_run() in MLSpec (see ImageNet tutorial notebook for details).