API: MLSpec: Training and Inference
Overview
This is the most important class in RapidFire AI’s API to define your training and inference code, including for example preprocessing, model definition, and custom evaluation metrics.
Your MLSpec class must be specified in a separate Python file and given as argument to an
Experiment constructor; so, each experiment is associated with a given class definition.
You can iteratively explore variations of code for your MLSpec functions on the same notebook,
but to try any changes to your MLSpec code, you must instantiate a new experiment.
See the API: Experiment Ops page for more on the experiment constructor.
The MLSpec class has the following key functions and semantics:
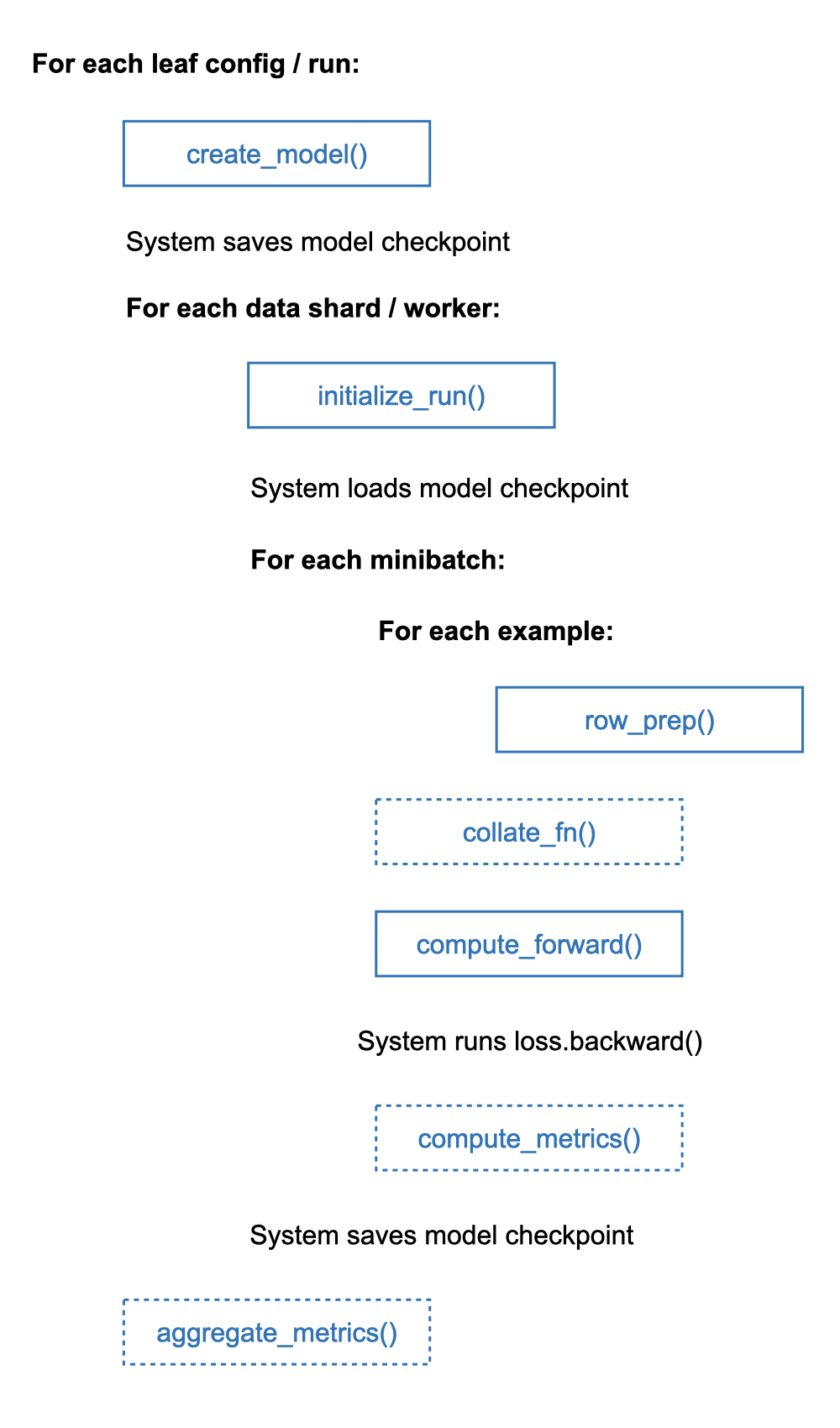
initialize_run(): Initialize read-only in-memory data structures for a run.create_model(): Create and return annn.Moduleobject for a run.row_prep(): Preprocess a single injected row/example from an ESF to get tensors.collate_fn(): (Optional) Override default PyTorch collate for variable-length examples.compute_forward(): Define the forward pass and return the loss and outputs on one minibatch.compute_metrics(): (Optional) Define your own custom eval metrics overcompute_forward()outputs.aggregate_metrics(): (Optional) Aggregate your metrics acrosscompute_metrics()outputs of all minibatches per epoch.
The flowchart below show the control flow of how the system orchestrates these functions
for one epoch of training for a given set of runs collectively (run_fit()).
Validation computation is invoked at the end of every training epoch if the validation
partition is provided in the data handle; it does not perform the backward step, of course.
Likewise, testing and prediction computations also have similar control flows.
We elaborate on each function below and illustrate each with usage from the IMDb or ImageNet tutorial notebooks.
This class supports large models that may not fit on a single GPU–you do not need to do anything extra (e.g., write separate DeepSpeed or FSDP configs) because RapidFire AI automates model scaling for you. But as of this writing, a model for the given batch size must fit in the aggregate GPU memory of a single multi-GPU machine. We plan to continue expanding this API and add more model scaling functionality based on feedback.
Initialize Run
Define any data structures once for a run (a single config combo) that can be reused across other functions in this class.
- initialize_run(self, misc_path: str, cfg: Dict[str, Any], mode: str) None:
- Parameters:
misc_path (str) – Directory with miscellaneous files listed under a “misc” locator in a data handle; injected by system
cfg (Dict[str, Any]) – A single config knob dictionary from the config group given to
run_fit(); injected by systemmode (str) – Enum to indicate the data partition type; injected by system; values can be “train”, “test”, “validation”, or “predict”
- Returns:
None
- Return type:
None
Examples:
# From News tutorial notebook
def initialize_run(self, misc_path: str, cfg: Dict[str, Any], mode: str):
import evaluate
from transformers import AutoTokenizer
self.tokenizer = AutoTokenizer.from_pretrained(cfg["model_type"])
self.rouge = evaluate.load("rouge")
# From ImageNet tutorial notebook
def initialize_run(self, misc_path: str, cfg: Dict[str, Any], mode: str):
import os
import json
if (mode == "predict"):
path = os.path.join(misc_path, "imagenet_label_mapping.json")
with open(path, 'r', encoding='utf-8') as f:
self.class_to_idx = json.load(f)
Notes:
Any objects created in this function must be immutable (read-only) after creation. This is not for sharing any writable state across minibatches; that can lead to non-deterministic system behaviors. Such shared initialization of read-only objects helps keep your ML code modular and can also improve its efficiency.
In the News example above, we create a tokenizer based on the model type that is given as a user knob in config dictionary. This tokenizer is then reused for the forward pass across all minibatches.
In the ImageNet example above, we just load the mapping between label numbers and strings. This can be used, say, when writing prediction outputs for easier readability. Note that this one does not use any run-specific knobs from the config dictionary, i.e., it is the same for all runs.
Row Preprocess
Function to preprocess a single injected row/example from an Example Structure File.
You can open any object files listed in a column, apply data structures created in initialize_worker(),
and/or use other relevant libraries based on the file types and data modalities involved.
Your internal code pathway for this function must account for whether the data has targets/labels are not.
- row_prep(self, row, cfg: Dict[str, any], mode: str) Dict[str, Any] | List[Any] | Tuple[Any]
- Parameters:
row (DataFrame) – A single row from the Example Structure File as a pandas
DataFramerow; injected by systemcfg (Dict[str, Any]) – A single config knob dictionary from the config group given to
run_fit(); injected by systemmode (str) – Enum to indicate the data partition type; injected by system; values can be “train”, “test”, “validation”, or “predict”
- Returns:
Dictionary with user-set string as key and any object as value, or a list/tuple of objects. If you do not give a custom
collate_fn()the object type here must all betorch.Tensor; the return value must be compatible with the default PyTorchcollate_fn()and its member cannot be None.- Return type:
Dict[str, Any] | List[Any] | Tuple[Any]
Examples:
# From IMDb tutorial notebook
def row_prep(self, row, is_predict: bool):
import torch
from transformers import AutoTokenizer
texttok = self.tokenizer(row['text'], return_tensors="pt", truncation=True, padding="max_length")
out = {"input_ids": texttok["input_ids"].squeeze(),
"attention_mask": texttok["attention_mask"].squeeze()}
if mode != "predict":
out["labels"] = torch.tensor(row['label'])
return out
# From ImageNet tutorial notebook
def row_prep(self, row, is_predict: bool):
import torch
from PIL import Image
from torchvision import transforms
pil_image = Image.open(row['filepath']).convert('RGB')
image = self.transform(pil_image)
out = {"images": image}
if mode != "predict":
out["labels"] = torch.tensor(row['label'])
return out
Notes:
This function is highly general and supports preprocessing for all data modalities in a unified manner.
You write this for a single example/row, analogous to the Map function in the MapReduce API.
The row injected here is simply a single DataFrame row from your ESF.
This function will be used automatically during loading of data batches when run-fit() is invoked.
Since this function also takes cfg, it lets you rapidly experiment with alternate forms of
data preprocessing in one go in a single run_fit() based on appropriate user knobs.
For instance, you can explore different image resizing options, or image data augmentation strategies,
or text tokenization truncation/padding options across alongside different hyper-parameters.
The flag mode helps you tell if label/target columns are present so that you can preprocess them too.
You can also preprocess train and validation/test partitions differently if you want.
The first example above is for IMDb, which has all data in-situ (i.e., no object columns).
We simply pad and/or truncate all examples to a constant length.
Since there is no custom collate, all returned objects must be torch.Tensor type.
Also note the squeeze() is applied to the first two objects to ensure their tensor dimensions are
consistent with what the default PyTorch collate_fn() expects.
The second example above is for ImageNet, which has one object column with images.
In the backend, RapidFire AI automatically ingests all object files in a massively parallel manner.
So, when you open the object file, it become a local file.
You can apply any transforms and write out its tensors.
Note that the label, which is an integer in both examples, must also be typecast with torch.tensor()
to ensure consistency of return types.
Custom Collate
Optional function to override default PyTorch collate_fn() with your custom collation of variable-sized
examples into a batch.
It works with your row_prep() returned objects; so, handle the injected inputs accordingly.
- collate_fn(self, batch: List[Any], cfg: Dict[str, Any], mode: str
- ) -> (torch.Tensor |
- Tuple[torch.Tensor | Dict[str, torch.Tensor] | List[torch.Tensor]] |
- Dict[str, torch.Tensor] |
- List[torch.Tensor] |
- List[Dict[str, torch.Tensor]]):
- Parameters:
batch (List[Any]) – List of objects returned by your
row_prep()for a batch of examples; injected by systemcfg (Dict[str, Any]) – A single config knob dictionary from the config group given to
run_fit(); injected by systemmode (str) – Enum to indicate the data partition type; injected by system; values can be “train”, “test”, “validation”, or “predict”
- Returns:
Single tensor or a Tuple/Dict/List of tensors or recursively of Tuple/Dict/List of tensors; all top level tensors must have the batch size as the outermost dimension
- Return type:
torch.Tensor | Dict[str, torch.Tensor] | List[torch.Tensor] | Tuple[torch.Tensor] | List/Dictionary/Tuple of preceding types recursively
Example:
# From IMDb extended tutorial notebook
def collate_fn(self, batch, is_predict):
import torch
import transformers
#Get unpadded dict for collate but still truncate all to model max length
texts = [row["text"] for row in batch]
texttok1 = self.tokenizer(texts, return_tensors=None, truncation=True, padding=False)
batch_max = max(len(ex) for ex in texttok1["input_ids"])
#Retokenize with padding to batch_max and get tensors
texttok2 = self.tokenizer(texts, padding='max_length', truncation=True, max_length=batch_max, return_tensors="pt")
out = {"input_ids": texttok2["input_ids"],
"attention_mask": texttok2["attention_mask"]}
if not is_predict:
labs = [row["labels"] for row in batch]
out["labels"] = torch.tensor(labs)
return out
# From COCO tutorial notebook
def collate_fn(self, batch, cfg: Dict[str, Any], mode: str):
inputs, targets = tuple(zip(*batch))
return inputs, targets
Notes:
This optional function gives you full flexibility to customize collation for different data modalities.
Please make sure it works correctly in conjunction with your row_prep() returned values.
It will be used automatically during loading of data batches when run_fit() is invoked.
The first example above is for IMDb in which we do not tokenize the example in row_prep().
Rather we identify the longest string in the batch and pad all tokenized strings to only that length,
truncated at the model’s internal max_length.
Note that the HF tokenizer does not return tensor type in the first usage (returns lists of
token IDs) but does so in the second call.
The second example above is for COCO in which we have variable-length lists of tensors in the complex target dictionary across examples. And since images for segmentation use cases can be of variable sizes, it is not typical to resize or pad them. So, we just zip the batch’s examples to collate inputs (image tensors) and targets separately, knowing that each example’s tensors could be of different sizes.
Create Model
Instantiate a single model architecture based on your config knobs to run gradient descent on or do inference with.
Example:
# From IMDb tutorial notebook
def create_model (self]):
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("lvwerra/distilbert-imdb")
return model
# From ImageNet tutorial notebook
def create_model (self, cfg: Dict[str, Any]):
import torchvision as tv
from transformers import ViTForImageClassification
#Import a pretrained model for finetuning from torchvision or huggingface
if cfg["model_type"] == "resnet":
return tv.models.resnet50(weights=tv.models.ResNet50_Weights.IMAGENET1K_V1)
elif cfg["model_type"] == "vgg":
return tv.models.vgg16(weights=tv.models.VGG16_Weights.IMAGENET1K_V1)
elif cfg["model_type"] == "vit":
return ViTForImageClassification.from_pretrained("google/vit-base-patch16-224-in21k", num_labels=1000)
else:
return tv.models.resnet50(weights=None)
Notes:
This is an important function in MLSpec that gives you full flexibility to define whatever model
architecture you want with multiple pathways to create it.
You need not worry if the model is larger than GPU memory and do not need to write lower level configurations for packages such as DeepSpeed, FSDP etc.
You can also use your user-given knobs from the injected config dictionary to instantiate a model accordingly.
This means you to compare different model architecture specifics in one go in the same run_fit().
You can instantiate a model via any of the following three pathways:
Import a pretrained model from model hubs such as
torchvision, HFtransformers, HFdiffusers, etc. The above examples show models being imported from both HFtransformers(adistilbert-imdbmodel for IMDB and avit-base-patch16-224-in21kmodel for ImageNet) and fromtorchvision(resnet50andvgg16). In particular, note how the user-knobmodel_typeis used in the ImageNet example to pick a model architecture.Load your own model checkpoint from an absolute path on remote storage (S3 for now) using
load_model()below,
which you can use inside your create_model().
Instantiate your own custom
nn.modulearchitecture. For this, you must define your architecture as a class
in a separate .py file that is uploaded to the same folder on Jupyter as your notebook. Import your class and instantiate it in this function, akin to importing a model from a library.
The above flexibility enables you to straddle the full DL customization spectrum with this one function. For instance, you can do custom transfer learning here, e.g., import a pretrained model from a library but add custom head layers, or chop off or freeze some layers. You can also mix and match pretrained models/layers with new layers, say, for multimodal use cases.
While RapidFire AI supports out of the box training for large models that do fit on a single GPU, as of this writing, a given model for the given training batch size must fit in the aggregate GPU memory of a single multi-GPU machine. We plan to continue expanding this API and add more functionality based on feedback.
Load Model
Optional utility function to load your own model checkpoint from the models directory in your locators.
You do NOT implement this function, but rather you just use it inside create_model().
- load_model(self, model_tag: str) Any
- Parameters:
model_tag (str) – Absolute path to model checkpoint on remote storage (S3 for now)
- Returns:
Loaded model object to be used inside your
create_model()- Return type:
Any
Example:
# Import a checkpointed imdb finetuned model from model directory
mymodel = load_model("imdb-finetuned-checkpoint.pt")
Notes:
The loaded model object can technically be of any type.
But when this function is used inside create_model(), the return type of that function must be nn.Module.
Forward Pass
Define the forward pass of the given model on the given minibatch to define the loss function (for train/val/test partitions alone) and compute the outputs (for all partitions).
- compute_forward(self, model: nn.Module, minibatch: torch.Dataset, cfg: Dict[str, Any], mode: str) Tuple[torch.Tensor, Dict[str, Any]] | Dict[str, Any]:
- Parameters:
model (nn.Module) – A single model object returned by your
create_model(); injected by systemminibatch (torch.Dataset) – A single minibatch from the dataset with
batch_sizelisted incfg; injected by systemcfg (Dict[str, Any]) – A single config knob dictionary from the config group given to
run_fit(); injected by systemmode (str) – Enum to indicate the data partition type; injected by system; values can be “train”, “test”, “validation”, or “predict”
- Returns:
For train/validation/test paths: a 2-tuple with the loss value and a dictionary of outputs with user-set string keys and object values; for predict path: only the dictionary of outputs
- Return type:
Example:
# From ImageNet tutorial notebook
def compute_forward(self, model, minibatch, cfg, mode):
import torch
import torch.nn.functional as F
if mode != "predict":
if cfg["model_type"] == "vit":
outputs = model(pixel_values=minibatch["images"], labels=minibatch["labels"])
loss = outputs.loss
logits = outputs.logits
else:
logits = model(minibatch["images"])
loss = F.cross_entropy(logits, minibatch["labels"])
#logits is required for top5_accuracy named-metric; predictions is required for top1_accuracy named-metric.
return loss, {"logits": logits, "predictions": torch.argmax(logits, dim=1), "targets": minibatch["labels"]}
else:
if cfg["model_type"] == "vit":
outputs = model(pixel_values=minibatch["images"]).logits
else:
outputs = model(minibatch["images"])
return {"logits": outputs, "predictions": torch.argmax(outputs, dim=1)}
# From IMDb tutorial notebook
def compute_forward(self, model, minibatch, cfg, mode):
import torch
outputs = model(**minibatch)
logits = outputs.logits
outdict = {"predictions": torch.argmax(logits, dim=1)}
if mode != "predict"
outdict["targets"] = minibatch["labels"]
loss = outputs.loss
return loss, outdict
return outdict
Notes:
This is another important function in MLSpec that gives you full flexibility to define an
auto-differentiable loss function on your model and compute its outputs.
It abstracts away typical boilerplate code for invoking backward pass (backprop), looping over minibatches, wrestling with data loaders, or looping over epochs. Thus, you need not worry about the dataset size, where it is loading from, how to cache it, etc. or wrestle with configuring low-level tools such as DDP.
And again, just like with create_model() you need not worry if the model is small or large,
and if it is large worry about wrestling with configuring low-level tools such as FSDP, DeepSpeed, etc.
By abstracting away such complexity on both data scale and model scale, RapidFire AI ensures seamless and consistent training and inference on large datasets and/or large models.
In this function, you can use your user-given knobs from the injected config knob dictionary to define
the forward pass accordingly.
In the ImageNet example above, note how the code paths differ for ViT (from HF transformers) and others
(from torchvision).
The HF model object has the loss function defined internally; so, we need not define it again.
But for the torchvision model we define the loss explicitly using cross_entropy() from the
torch.nn.functional library.
Also, depending on the value of mode this function must satisfy the following:
mode="train": Define the loss function and return the loss value in the 2-tuple. Typecast the loss value as atorch.Tensorobject of shape(1,).mode="validation"|"test": Optionally still return the loss value in the 2-tuple (or zero tensor) or only the outputs dictionary.mode="predict": Return only the outputs dictionary.
In general, the outputs dictionary can have any string-object key-value pairs you like, e.g., logits, predicted objects, etc.
Each value entry must be batch_size long in its outermost dimension (as a tensor, list, etc.).
Furthermore, if you listed supported named-metrics in your config knobs, the outputs dictionary must include the following:
If the named-metric
top1-accuracyis given, outputs dictionary must contain 2 key-value pairs with reserved string keys as follows:predictions, the model’s actual output onminibatchas a tensor, andtargets, the labels fromminibatchitself.If the named-metric
topk-accuracy(k > 1) is given, outputs dictionary must contain 2 key-value pairs with reserved string keys as follows:logits, the model’s final logits onminibatchas a tensor, andtargets, the labels fromminibatchitself.
Custom Metrics Definition
Optional function to define your own custom metrics based on the model’s outputs, loss, and minibatch. These are minibatch-level metrics for train/validation/test partitions only and they get auto-plotted on MLflow for train/validation.
- compute_metrics(self, loss: torch.Tensor, outputs: Dict[str, Any], minibatch: torch.Dataset, cfg: Dict[str, Any], mode: str) Dict[str, torch.Tensor | Any]
- Parameters:
loss (torch.Tensor) – Loss value returned in your
compute_forward(); injected by systemoutputs (Dict[str, Any]) – Outputs dictionary returned in your
compute_forward(); injected by systemminibatch (torch.Dataset) – A single minibatch from the dataset with
batch_sizelisted incfg; injected by systemcfg (Dict[str, Any]) – A single config knob dictionary from the config group given to
run_fit(); injected by systemmode (str) – Enum to indicate the data partition type; injected by system; values can be “train”, “test”, “validation”, or “predict”
- Returns:
Dictionary of metrics where a key is a user-given string and a value is a torch.Tensor of shape (1,) or any non-tensor object that is appendable across minibatches
- Return type:
Dict[str, torch.Tensor | Any]
Example:
# From ImageNet tutorial notebook
def compute_metrics(self, loss, outputs, minibatch, cfg):
import torch
labels = minibatch["labels"]
correct = (outputs["predictions"] == labels).sum()
total = torch.tensor(labels.size(0))
return {'correct': correct, 'total': total}
Notes:
In the example above, we (redundantly) show the calculations involved for the named-metric top1_accuracy by decomposing the number of correct predictions and the total number of predictions so that they can be added separately and divided later.
For Tensor-valued (including scalars) custom metrics, they must be additive across minibatches. For instance, the total number of correct predictions across 10 minibatches is simply the addition of the number of correct predictions of each minibatch.
For non-Tensor custom metrics, the semantics of how RapidFire AI handles them across per-GPU partitions of a minibatch is that they are appended into a single List per minibatch, which is part of one row of the DataFrame sent into aggregate_metrics().
Custom Metrics Aggregation
Optional function to aggregate your custom metrics output by compute_metrics() across all minibatches of the dataset every epoch. These are epoch-level metrics for train/validation/test and they get auto-plotted on MLflow for train/validation.
- aggregate_metrics(self, metrics: pandas.DataFrame, cfg: Dict[str, Any], mode: str) Dict[str, float]
- Parameters:
metrics (pandas.DataFrame) – A table with one column per key in the output dictionary of your
compute_metrics()and one row per minibatch in the datasetcfg (Dict[str, Any]) – A single config knob dictionary from the config group given to
run_fit(); injected by systemmode (str) – Enum to indicate the data partition type; injected by system; values can be “train”, “test”, “validation”, or “predict”
- Returns:
Dictionary of aggregated metrics where a key is a user-given string and a value is a float
- Return type:
Example:
# From ImageNet tutorial notebook
def aggregate_metrics(self, metrics: pd.DataFrame, cfg: Dict[str, Any]) -> Dict[str, float]:
correct = sum(metrics['correct'])
total = sum(metrics['total'])
return {'accuracy': correct / total}
Notes:
In the example above, we (redundantly) show the calculations involved for the named-metric top1_accuracy by decomposing the number of correct predictions and the total number of predictions. Note how they are added separately first across all minibatches and then divided.
In general, such metrics that have decomposable components that are additive across minibatches but then can be assembled into a final result with additional arithmetic are called algebraic metrics.
As of this writing, the RapidFire AI API can already support any algebraic metrics via the above two functions (compute_metrics() and aggregate_metrics()).
For non-algebraic metrics, you can use the non-tensor metrics pathway in compute_metrics() that lets you return whatever object you want per minibatch and post-process those objects across all minibatches in one go per epoch in this function. For an example of non-algebraic metrics, please see the COCO object detection+segmentation use case for all benchmark metrics from pycocotools.
We plan to continue expanding this API and might add support for more types of metrics based on feedback.
Early Stopping Check
Optional function to define custom convergence or early stopping check on a per-run based on the number of epochs it has completed and all of its validation partition metrics across all epochs so far.
- has_converged(self, val_metrics: pandas.DataFrame, epoch: int, cfg: Dict[str, Any]) bool
- Parameters:
val_metrics (pandas.DataFrame) – A table with one column per key in the output dictionary of your
aggregate_metrics(), one for each named-metric, and one for validation loss; one row per epoch completed so far by this config’s run/model; injected by systemepoch (int) – The number of epochs completed so far by this config’s run/model; injected by system
cfg (Dict[str, Any]) – A single config knob dictionary from the config group given to
run_fit(); injected by system
- Returns:
Whether this config’s run has converged or not based on your criteria calculated using the other inputs
- Return type:
Example:
# From ImageNet extended tutorial notebook
def has_converged(self, val_metrics, epoch, cfg) -> bool:
# Stop if user-defined accuracy metric exceeds absolute value of 0.5
if cfg["model_type"] == "vit":
return (val_metrics["accuracy"].iloc[-1] > 0.5)
# Stop if over 10 epochs and delta rise in top5_accuracy over previous two epochs is less than 0.005
diff = val_metrics["top5_accuracy"].iloc[-1] - val_metrics["top5_accuracy"].iloc[-2]
return ((epoch > 10) and (diff < 0.005))
Notes:
In the example above, we define a complex boolean function involving epoch count, named-metric top5_accuracy, and user-defined custom metric accuracy to ascertain when a given run has converged as per our application criteria.
This function is applied independently to all runs that are part of the same run_fit() at the end of every epoch. So, on the MLflow plots you might see some runs stopping early when they satisfy this function. Likewise, the status table on the Jupyter notebook will indicate which runs have converged.
Note that if you provide both this function in MLSpec and the reserved key string epochs in the config (or config-group) knob dictionary, the semantics are that epochs value will be the upper bound on number of epochs for each run.